Dify v1.1.0: Lọc Dữ Liệu Tri Thức Nâng Cao với Metadata Tùy Chỉnh
Dify v1.1.0: Lọc Dữ Liệu Tri Thức Nâng Cao với Metadata Tùy Chỉnh
Dify v1.1.0: Lọc Dữ Liệu Tri Thức Nâng Cao với Metadata Tùy Chỉnh
Chào mọi người! Yawen từ đội ngũ sản phẩm Dify đây. Hôm nay, chúng mình rất vui mừng giới thiệu phiên bản Dify v1.1.0 với tính năng mới toanh: Lọc Tri Thức bằng Metadata.
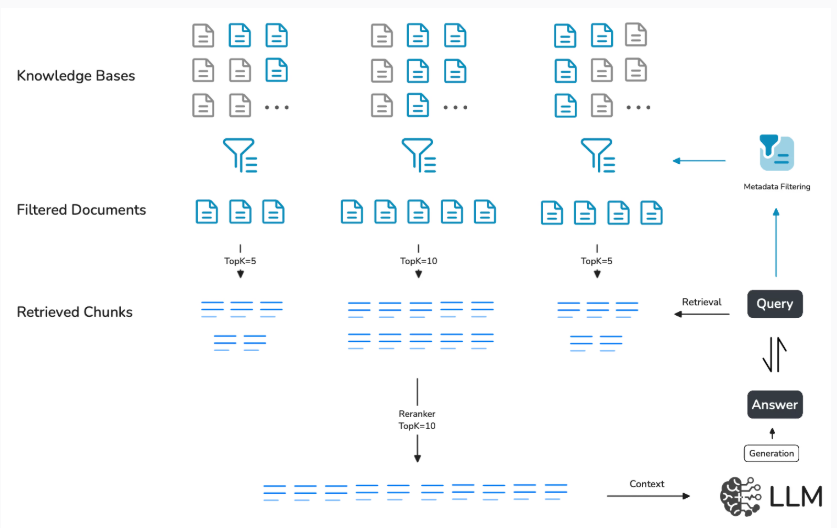
Tính năng này sẽ giúp bạn tìm kiếm và lấy dữ liệu chính xác hơn trong kho tri thức của mình, nhờ vào việc sử dụng các thuộc tính metadata tùy chỉnh. Trước đây, bạn có thể phải lục tung cả một đống dữ liệu khổng lồ mà không có cách nào lọc hay kiểm soát, khiến việc tìm thông tin quan trọng trở nên khó khăn.
Nhưng giờ đây, với metadata, dữ liệu của bạn sẽ được gắn thẻ và phân loại một cách thông minh, giúp tăng tốc độ và độ chính xác khi tìm kiếm. Điều này đặc biệt hữu ích trong bối cảnh RAG (retrieval-augmented generation), nơi bạn cần quản lý và truy cập lượng lớn thông tin một cách hiệu quả.
Metadata là gì vậy?
Hiểu đơn giản, metadata là "dữ liệu về dữ liệu". Nó cung cấp thêm thông tin hoặc thuộc tính mô tả dữ liệu chính, giúp bạn tìm kiếm và lấy thông tin chính xác hơn. Ví dụ, trong một hệ thống quản lý tài liệu, metadata có thể bao gồm tên tài liệu, tác giả, ngày tạo,... Nhờ có cấu trúc thông tin này, hệ thống có thể lọc kết quả dựa trên các tiêu chí cụ thể, giúp bạn tìm thấy nội dung phù hợp một cách nhanh chóng.
Lợi ích của việc lọc bằng Metadata:
- Tìm kiếm chính xác hơn: Nhanh chóng tìm thấy tài liệu liên quan, giảm thiểu kết quả không cần thiết.
- Tăng cường bảo mật: Kiểm soát quyền truy cập, đảm bảo chỉ người được phép mới xem được thông tin nhạy cảm.
- Tối ưu hiệu suất: Thu hẹp phạm vi tìm kiếm, cải thiện hiệu quả và tiết kiệm tài nguyên.
- Nâng cao trải nghiệm người dùng: Dễ dàng điều hướng và tìm kiếm trong kho tài liệu lớn, đặc biệt hữu ích trong môi trường doanh nghiệp.
Hình dung về kiểm soát truy cập:
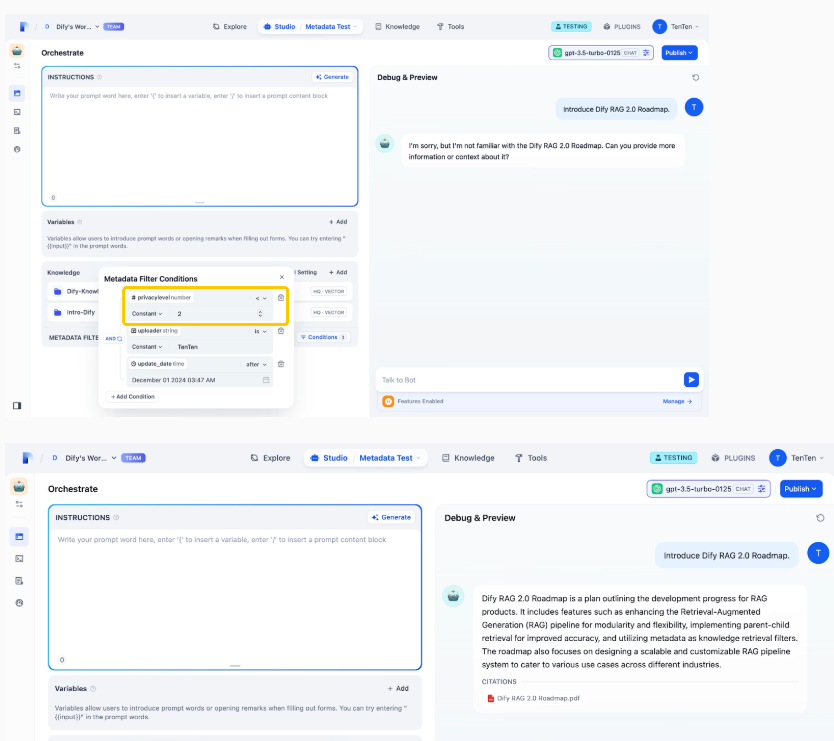
Hãy xem sơ đồ bên dưới để thấy rõ hơn cách lọc metadata giúp quản lý quyền truy cập hiệu quả. Trong ví dụ này, chúng ta sử dụng ba tiêu chí lọc: privacylevel, uploader, và update_date.
Bằng cách điều chỉnh privacylevel, bạn có thể kiểm soát ai được phép xem RAG 2.0 Roadmap. Điều này giúp quản trị viên dễ dàng quản lý quyền truy cập và đảm bảo an toàn cho dữ liệu.
Tóm lại, metadata giống như một bộ lọc tri thức thông minh, giúp bạn tìm kiếm thông tin hiệu quả, an toàn và chính xác hơn. Điều này đặc biệt quan trọng trong các hệ thống RAG (retrieval-augmented generation), nơi việc bảo vệ quyền riêng tư và đảm bảo thông tin phù hợp là yếu tố then chốt.
Hướng dẫn sử dụng Metadata Filter
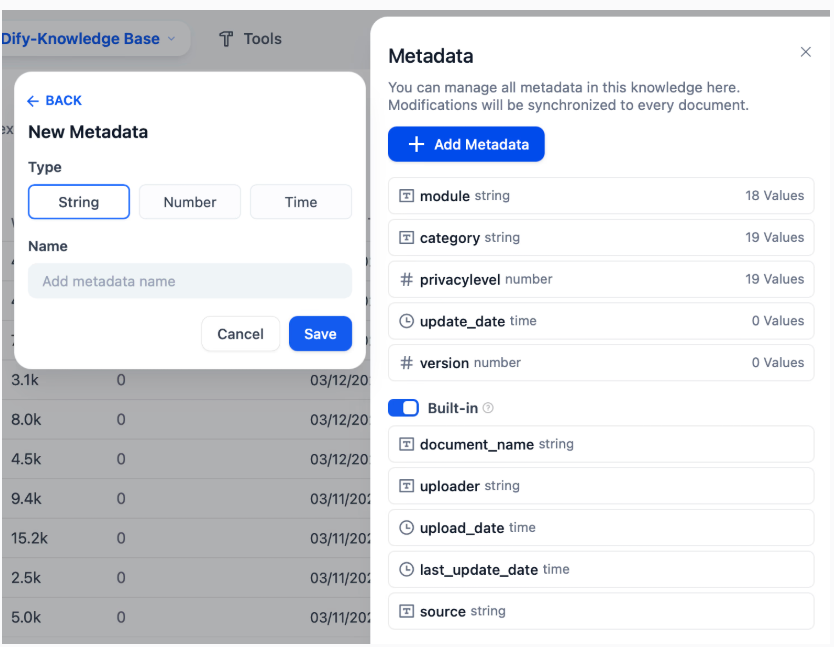
Bước 1: Thêm Metadata vào Tài Liệu trong Kho Tri Thức
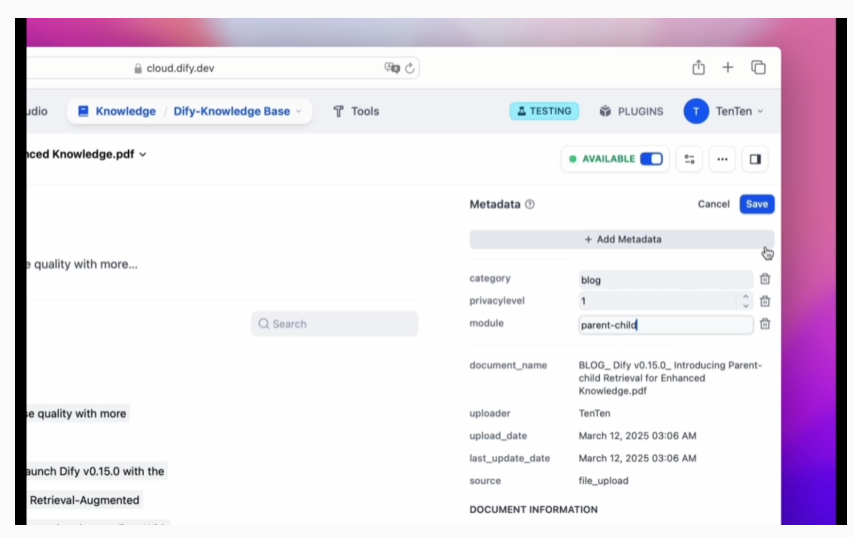
Người dùng có thể dễ dàng thêm và quản lý metadata cho tài liệu trong kho tri thức. Khi tạo tài liệu, hệ thống sẽ tự động gán một số metadata mặc định như tên file, người tải, ngày tải,... Bạn cũng có thể tự thêm các trường metadata mới, đặt tên và chọn kiểu dữ liệu, cũng như chỉnh sửa hàng loạt các tài liệu hiện có. Quá trình gắn thẻ này giúp bạn thêm thông tin có cấu trúc vào tài liệu, giúp việc tìm kiếm và quản lý sau này dễ dàng hơn rất nhiều.
Bước 2: Cấu Hình Lọc Metadata trong Ứng Dụng
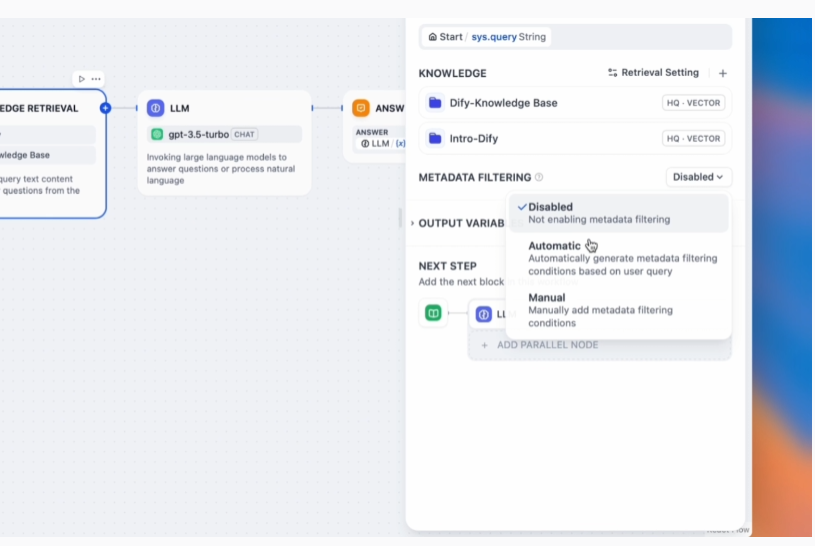
Bạn có thể tìm thấy tính năng lọc metadata trong phần Context của Chatbot hoặc nút Knowledge Retrieval của Chatflow hoặc Workflow. Tính năng này cho phép bạn lọc và lấy thông tin dựa trên các thuộc tính metadata một cách chính xác.
Bạn có thể chọn giữa hai chế độ lọc: tự động hoặc thủ công. Ở chế độ tự động, hệ thống sẽ tự động trích xuất và tạo điều kiện lọc từ truy vấn của người dùng. Khi cấu hình thủ công, bạn có thể đặt điều kiện lọc dựa trên kiểu trường metadata (ví dụ: chuỗi, số, thời gian) và thiết lập mối quan hệ giữa nhiều điều kiện (AND hoặc OR).
Ba Loại Metadata Phổ Biến và Ứng Dụng Của Chúng
Chúng tôi hỗ trợ ba loại metadata chính: chuỗi, số và thời gian. Mỗi loại có thể được áp dụng linh hoạt tùy theo nhu cầu sử dụng thực tế. Dưới đây là một vài ví dụ:
- Metadata Chuỗi (String): Giúp tìm kiếm thông tin liên quan một cách hiệu quả. Ví dụ: khi bạn tìm kiếm "báo cáo dự án", các thẻ metadata như "Marketing" hoặc "R&D" sẽ đảm bảo chỉ các tài liệu liên quan đến các phòng ban hoặc dự án cụ thể này được trả về.
- Metadata Số (Number): Kiểm soát quyền truy cập dựa trên các tiêu chí định trước. Ví dụ: bạn có thể chỉ cho phép người dùng xem các tài liệu có mức độ bảo mật trên một ngưỡng nhất định, đảm bảo an toàn và phù hợp cho dữ liệu.
- Metadata Thời Gian (Time): Phân biệt giữa các phiên bản tài liệu cũ và mới. Khi nội dung được cập nhật và tải lại, việc lọc theo thời gian sẽ đảm bảo kết quả tìm kiếm ưu tiên phiên bản mới nhất. Ngoài ra, nếu người tải là chính bạn, bạn có thể dễ dàng so sánh các phiên bản khác nhau đã tải lên trong các đợt khác nhau với quy trình xử lý tài liệu nhất quán.
Nếu bạn muốn tìm hiểu chi tiết hơn về cách sử dụng tính năng này, hãy tham khảo tài liệu hướng dẫn tại Knowledge Base|Dify và tự mình trải nghiệm trên Dify.AI nhé!
Vui lòng đăng nhập để viết bình luận!
Youtube
0 Bình luận
Chưa có bình luận nào.